 Add text to get the translation that 22 AI models agree on
Add text to get the translation that 22 AI models agree on


Is AI translation accurate enough for business? The 2026 guide
AI translation in 2026 reaches approximately 96% accuracy across 133 languages. That number sounds reassuring until you do the arithmetic.
On a 10,000-word document, 96% accuracy means roughly 400 words are potentially wrong. You cannot identify which 400 without reading the entire output — and if you are reading the entire output anyway, you are already doing human review. That remaining 4% of errors concentrates in the errors that carry the most weight: mistranslated contract terms, incorrect dosages in medical content, reversed safety warnings.
The accuracy question is not whether AI translation is good. It clearly is, for a broad range of use cases. The question is whether it is good enough for your specific document, your specific language pair, and the specific consequences of the errors it produces.
This guide answers that question by document type, with real data from peer-reviewed research and current industry benchmarks. Buyers who have tried free AI tools and are asking "is this good enough for my contracts, my patient materials, my marketing campaigns?" will find a direct answer here for each content type they care about.
Table of Contents
- How accurate is AI translation in 2026?
- Why does AI translation accuracy vary so much by document type?
- Is AI translation accurate enough for legal documents?
- Is AI translation accurate enough for medical and clinical content?
- Is AI translation accurate enough for marketing and brand content?
- Is AI translation accurate enough for technical documentation?
- How does language pair affect AI translation accuracy?
- What does "fluent but wrong" mean and why does it matter?
- When is human review not optional?
- How does Tomedes' hybrid model solve the accuracy problem?
- FAQs
How accurate is AI translation in 2026?
Current benchmarking data shows AI translation reaching 96% accuracy across 133 languages in 2026, with that remaining 4% concentrated in the errors that carry the most weight: mistranslated contract terms, incorrect dosages in medical content, reversed safety warnings.
For high-resource language pairs (English to Spanish, French, German, or Portuguese), AI translation has achieved what researchers call near-human parity in general domains. Analysis of over 50 major research studies reveals that for high-resource language pairs in general domains, AI achieves COMET scores within 2–5% of professional human translation for English-French, English-German, and English-Spanish pairs.
For lower-resource languages and high-stakes domains, the picture is materially different. Significant quality gaps persist for low-resource languages (30–50% lower scores), high-stakes domains including legal and medical translation, and creative content requiring cultural adaptation and stylistic nuance.
The headline accuracy figure also masks a critical problem specific to AI systems: hallucination. Individual top-tier AI models carry a hallucination rate of 10–18% during translation tasks, according to data synthesized from the Intento State of Translation Automation 2025 and MachineTranslation.com internal benchmarks — a rate that is entirely unacceptable for a clinical consent form or a regulatory submission.

Hallucination in translation does not mean the model produces random output. It means the model produces confident, fluent text that is factually or semantically wrong — and that wrong text is indistinguishable from correct text without independent verification. A hallucinated legal clause reads like a real legal clause. A hallucinated dosage instruction reads like a real dosage instruction. The fluency that makes AI translation impressive is also what makes its errors dangerous.
Forrester Research data from 2025 puts the average enterprise cost of hallucination mitigation at approximately $14,200 per employee annually. Knowledge workers spend an average of 4.3 hours per week verifying AI outputs. In translation workflows, that verification burden falls on whoever owns the translated content — typically someone without linguistic expertise to catch the errors that matter most.
Why does AI translation accuracy vary so much by document type?
AI translation models are trained on large corpora of existing human text. Their accuracy on any given document depends on how well that document's language and structure resemble the data they were trained on.
General news content, conversational text, and straightforward informational writing are well-represented in training data. AI models handle these well. Legal language, medical clinical terminology, technical specifications, and culturally embedded marketing copy are all specialized registers that diverge significantly from training data patterns — and where the model's statistical pattern-matching produces confident but unreliable output.
Three specific failure patterns explain most of the accuracy variation by document type.
Domain-specific polysemy. Many words carry different precise meanings depending on the domain. "Clearance," a term standardly used in medical device manuals to mean regulatory authorization, is translated into another language by AI as physical clearance (a distance measurement) rather than the regulatory meaning. The model selects the most statistically common meaning of the word, not the contextually correct one. In a legal contract, "consideration" does not mean thoughtfulness. In a pharmaceutical label, "indication" does not mean a hint. Domain-specific polysemy is the most common source of plausible-sounding but consequentially wrong AI translations.
Jurisdictional and legal system variation. The German word "Gesellschaft" has been incorrectly translated by AI as "society" instead of the correct legal term "company" in business contracts. Legal terms like "consideration" or "discharge" have different meanings in different legal systems, which AI often fails to distinguish. The ambiguous Spanish pronoun "su" could be translated as "his," "her," "your," or "their" depending on context — potentially creating major disputes over property ownership in a legal document. Legal language is not only specialized, it is jurisdictionally specific. An AI model has no way of knowing which legal system's conventions apply to a given document without explicit context.
Cultural register and marketing creativity. Marketing language is built on connotation, implication, and cultural familiarity — the dimensions of meaning that are hardest to encode in training data. An AI model translating a brand tagline produces the most probable rendering of the words. It does not produce the rendering that resonates with the target audience's cultural frame of reference, humor register, or emotional associations. The output is accurate in a dictionary sense and wrong in a commercial sense.
Is AI translation accurate enough for legal documents?
For most legal documents used in formal proceedings, contracts, or regulatory contexts: no, not without qualified human review.
A 2023 comparative study revealed that AI translation tools had error rates of 15–25% when translating legal documents. Professional legal translators maintained accuracy above 98% for the same content. These errors included mistranslated terminology, incorrect interpretation of legal concepts, and structural issues that could change the meaning of entire clauses.
The practical consequence of a 15–25% error rate on a legal document is not minor stylistic inconsistency. It is clause-level meaning change. A mistranslated limitation-of-liability clause leaves one party exposed. A mistranslated condition precedent changes when an obligation triggers. A mistranslated definition changes every instance in which that defined term appears throughout the document.
A mistranslated contractual clause can alter the obligations or liabilities of parties involved, potentially resulting in prolonged litigation, financial loss, or damage to reputation. In one documented case, the English legal term "default judgment" was mistakenly translated as "judgment by default" in a French legal document, leading to confusion about the conditions under which a judgment could be contested.
There is also the certification problem. AI lacks legal accountability and cannot provide certifications required by courts or regulatory bodies. Certified translation (which USCIS, courts, academic institutions, and most regulatory bodies require for formal filings) requires a qualified human translator to personally attest to the accuracy and completeness of the translation. That attestation represents professional accountability that cannot be delegated to an AI system.
The verdict for legal documents: AI translation can serve as a useful first draft or internal comprehension tool. For any document that will be filed, submitted, signed, or cited in a formal proceeding, qualified human legal translation is required. Tomedes provides certified legal translation services under ISO 17100:2015 with domain-specialist legal translators.
Is AI translation accurate enough for medical and clinical content?
For patient-facing clinical content: no. The peer-reviewed evidence is unambiguous.
A September 2025 study published in JAMA Network Open compared AI translation of pediatric discharge instructions at Seattle Children's Hospital against professional human translation across four languages: Simplified Chinese, Somali, Spanish, and Vietnamese. AI translations were inferior across the board in Simplified Chinese, Somali, and Vietnamese. Even in Spanish (where AI performed closest to human translation), AI translations were inferior in meaning. A high proportion of clinically impactful errors were found for translations in languages other than Spanish, highlighting the need for caution when considering AI implementation in medical settings in its current form.
Discharge instructions are among the most consequential patient-facing documents a healthcare provider produces. A parent who misreads a discharge instruction for a sick child because the translation introduced a clinically impactful error is not a statistic in a benchmark study. A patient who takes an incorrect medication dose because the AI rendered a dosage instruction ambiguously is not a data point. These are real outcomes of real AI translation failures in real clinical settings, documented in a peer-reviewed journal by researchers at a major academic medical center.
According to a 2024 report by the American Medical Association, translation has become the most familiar AI use case for physicians. Between 2023 and 2024 alone, there was a 30% surge in the number of doctors who had either adopted or planned to implement these tools. However, Stanford University researchers published findings in February 2026 highlighting growing issues created by rapid AI translation adoption in healthcare settings across the US and a widening gap in standardized validation criteria and methods to ensure patient safety.
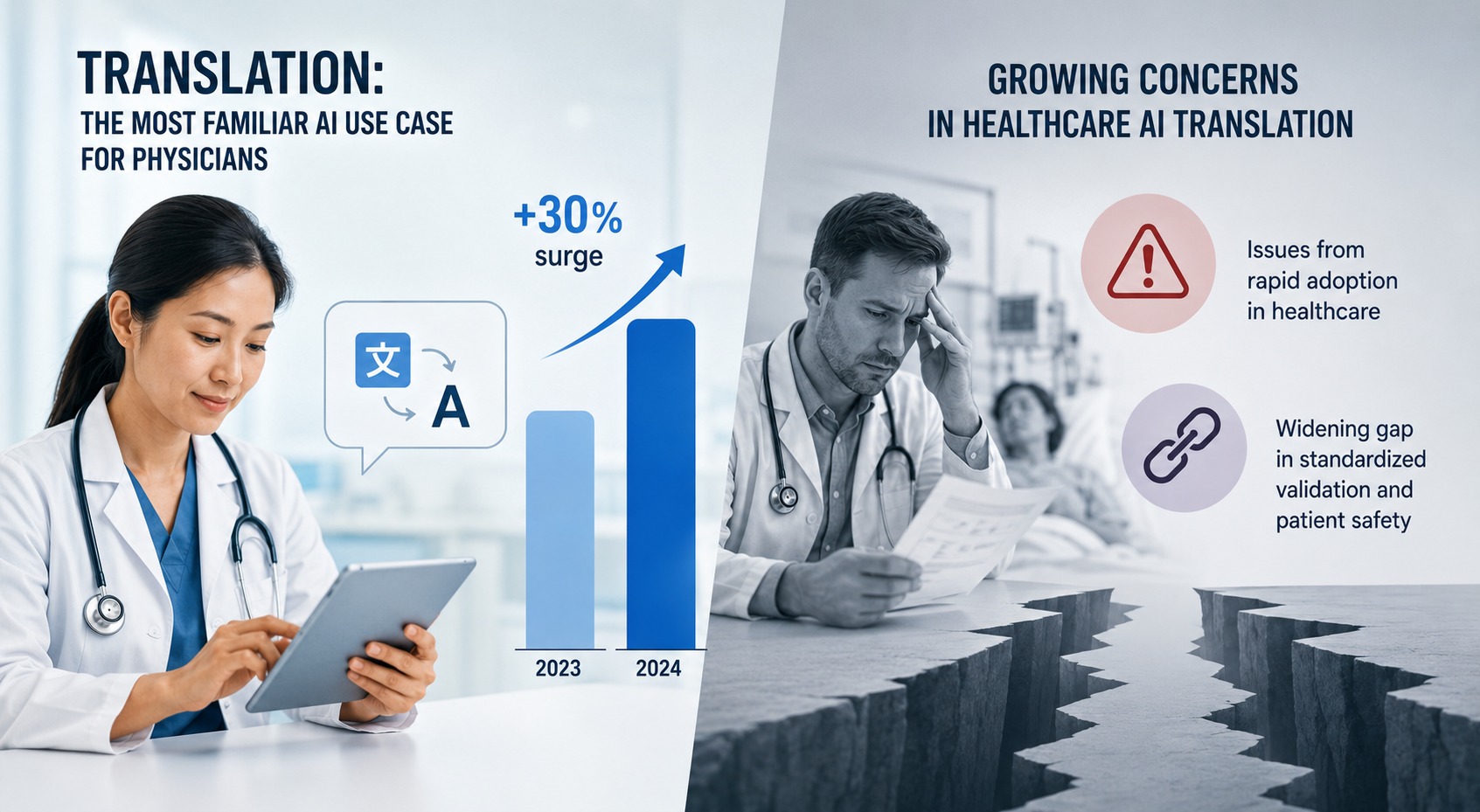
The speed and accessibility of AI translation in healthcare settings is real and valuable for triage purposes, helping clinicians communicate basic information when a professional interpreter is not immediately available. It is not appropriate as the production workflow for patient instructions, informed consent forms, pharmaceutical labeling, clinical trial documentation, or any content where a translation error carries patient safety implications.
The verdict for medical content: AI translation is not sufficient for patient-facing clinical materials in its current form, particularly for non-Spanish language pairs. Human review by a qualified medical translator is required for any content that affects patient understanding of their condition, treatment, or medication. Tomedes provides medical translation services certified under ISO 17100:2015 with medically qualified translators across all major language pairs.
Is AI translation accurate enough for marketing and brand content?
For brand-critical marketing content: no. For high-volume, lower-stakes marketing operations content: sometimes, with human oversight.
The accuracy problem in marketing translation is different from the accuracy problem in legal or medical translation. It is not primarily about factual error, AI translation of a product description is unlikely to reverse a safety warning. It is about the gap between accuracy and effectiveness.
When customers encounter poorly translated marketing content, 75% report decreased trust in the brand, and 64% say they are less likely to make a purchase, according to a 2024 consumer survey. High-profile translation failures have haunted major brands for years — HSBC's "Do Nothing" campaign mistranslation confused international customers, while KFC's "Eat your fingers off" Chinese slogan became a widely mocked example of translation gone wrong. These errors become permanently associated with brands and prove difficult to overcome in affected markets.
Marketing language is built on connotation, cultural resonance, and brand voice — precisely the dimensions where AI translation performs least reliably. An AI model translating a headline produces the most statistically probable rendering of the words. Brand voice is by definition not the most probable rendering — it is your company's specific, deliberate departure from the average.
For high-volume marketing operations content (product catalog descriptions, standard feature lists, templated email sequences, transactional notifications), AI translation with human brand review can work at scale if brand guidelines and an approved termbase are loaded into the workflow before translation begins. For campaign copy, brand narratives, taglines, and any content designed to create emotional resonance, human translation or transcreation is the appropriate tier. The cost of a brand translation failure in a new market is not the cost of fixing the translation. It is the cost of the brand impression already formed.
The verdict for marketing content: Tiered approach. AI with managed human review for high-volume operations content. Full human translation or transcreation for any content where brand voice, cultural resonance, and commercial effectiveness are the primary quality criteria.
Is AI translation accurate enough for technical documentation?
For structured, repetitive technical content: yes, with human post-editing.
Technical documentation (user manuals, product specifications, API documentation, knowledge base articles, software UI strings) is the content type where AI translation performs most reliably. The language is structured, terminology is consistent within a document, sentences are relatively short, and the content is information-dense rather than culturally embedded.
For high-resource language pairs in general domains including technical documentation, AI achieves COMET scores within 2–5% of professional human translation. For English to Spanish, French, German, or Portuguese technical content, AI translation quality is close enough to human translation that a qualified post-editor can efficiently close the gap — producing output that meets full post-editing quality standards at substantially lower cost than human translation from scratch.
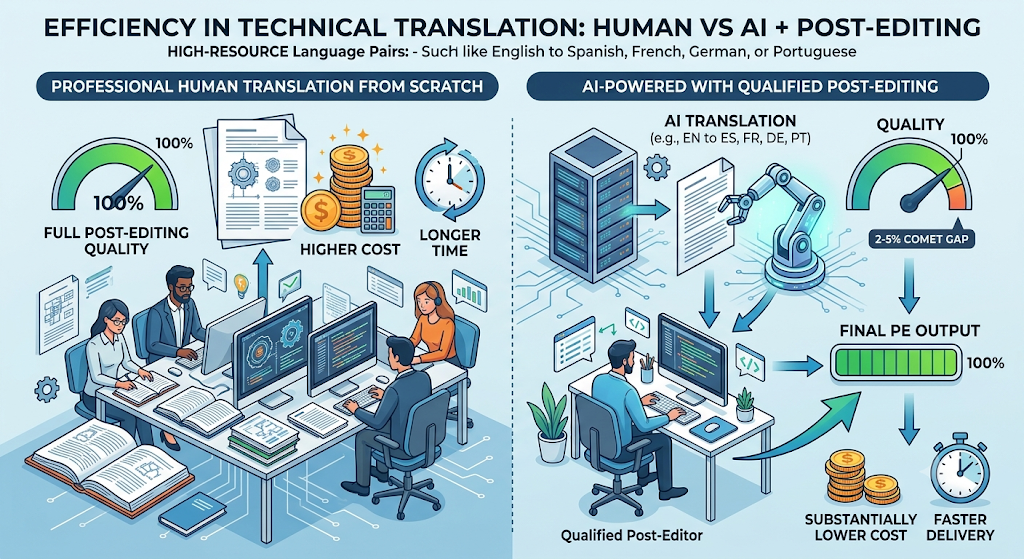
The qualifications matter. The content must be structured and consistent, highly idiomatic technical writing or source text with ambiguous phrasing degrades AI output significantly. The language pair must be well-supported, AI performs materially less well on technical content in lower-resource language pairs. And the domain terminology must be managed — without an approved termbase loaded into the workflow before translation, AI models will render the same technical term in multiple ways across a document.
Post-editing is what makes machine translation useful: if the tools are fast but the output is inconsistent, there is no efficiency gain. Some projects are simply not fit for MTPE and will produce poor outcomes regardless of the post-editor's skill.
The verdict for technical documentation: AI translation with full human post-editing (MTPE) is appropriate for high-volume, structured technical content in well-supported language pairs. Content with high terminology density, ambiguous source text, or lower-resource language pairs should be evaluated project-by-project before committing to a MTPE workflow.
How does language pair affect AI translation accuracy?
Language pair is the second most important variable after document type, and the one buyers most consistently underestimate.
AI translation accuracy is not uniform across languages. It reflects the amount and quality of training data available for each language pair. Languages with large digital text corpora (English, Spanish, French, German, Chinese, Japanese, Portuguese) have well-trained models that produce reliable output for appropriate content types. Languages with smaller digital footprints (many African languages, indigenous languages, some Southeast Asian languages, and less widely digitized Eastern European languages) produce substantially less reliable output.
Significant quality gaps persist for low-resource languages, with accuracy 30–50% lower than for high-resource pairs. For some language pairs, AI translation quality is low enough that MTPE is not a meaningful efficiency gain — the post-editor spends as much time correcting the AI draft as they would translating from scratch, while working from a starting point that may have introduced structural errors requiring full retranslation of affected segments.
The JAMA Network Open study referenced earlier demonstrates this pattern in a clinical setting. AI translation was inferior across the board in Simplified Chinese, Somali, and Vietnamese compared to professional human translation — while performing closest (though still inferior in meaning) in Spanish. Spanish is one of the best-supported AI translation language pairs in the world. Somali is among the least well-supported. The performance gap between them in a clinical accuracy study is a direct reflection of training data availability.
For buyers ordering AI translation in lower-resource language pairs (including many African languages, Punjabi, Somali, Vietnamese, and Tagalog), the default assumption that AI translation is "good enough as a starting point" should be verified against actual output quality before committing to a MTPE workflow. A project manager with expertise in the target language pair can assess MT quality on a sample before the full workflow is selected.
What does "fluent but wrong" mean and why does it matter?
"Fluent but wrong" is the specific failure mode that makes AI translation errors particularly dangerous compared to obvious machine translation errors of earlier generations.
Early machine translation produced output that was easy to identify as wrong — stilted syntax, garbled vocabulary, obviously non-native phrasing. A reader encountering poor early MT output immediately knew they were reading imperfect machine output. Modern neural machine translation and LLM-based translation produce output that reads like a fluent native speaker wrote it. The sentences are grammatically correct, the vocabulary is natural, the register is appropriate.
When that fluent-sounding output is also wrong (a mistranslated contract term, an incorrect dosage, a reversed safety warning), the error is invisible to anyone without the linguistic expertise to evaluate the translation against the source. A 2% error rate on a 10,000-word document is 200 words of potentially incorrect translation. At a standard reading speed, manually identifying those errors requires reviewing the entire output.
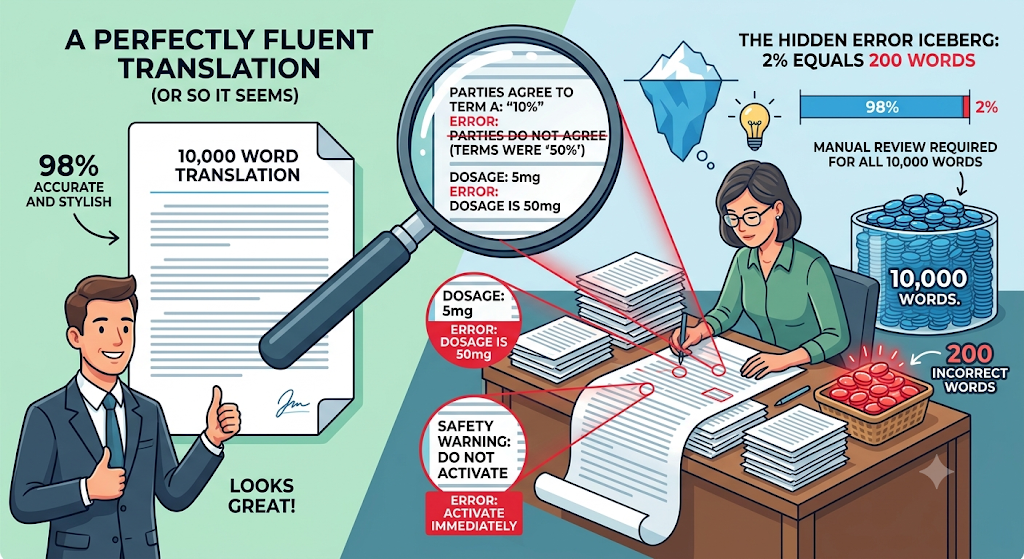
This is why the hallucination rate in translation matters more than the overall accuracy rate. Individual top-tier AI models carry a hallucination rate of 10–18% during translation tasks. A hallucination in translation is not garbled text — it is fluent, confident, incorrect text that requires domain expertise to identify. A legal professional reviewing a contract translation may catch a hallucinated clause. A procurement manager reviewing the same document probably will not.
The practical implication: for any content where a fluent-sounding error is consequential (legal, medical, regulatory, financial, or safety-critical), human review by a domain specialist is not a quality enhancement. It is the quality gate that the accuracy data shows AI cannot reliably supply.
When is human review not optional?
Human review is not optional when any of the following conditions apply.
The document requires certified translation. Certified translation requires a qualified human translator to attest to the accuracy and completeness of the translation. USCIS, courts, academic institutions, and most regulatory bodies will not accept AI-generated translations with a certification statement attached. The certification is a legal declaration of professional accountability, not a label that can be applied to automated output.
The content is patient-facing in a clinical setting. The JAMA Network Open evidence is clear: a high proportion of clinically impactful errors were found in AI translations of discharge instructions in non-Spanish language pairs. Patient safety cannot be managed through a 96% accuracy rate that concentrates its failures in medical terminology and clinical instruction language.
The document is a legal agreement with binding obligations. AI translation tools had error rates of 15–25% when translating legal documents. A 15–25% error rate on a binding contract is a material legal risk, not a translation quality footnote.
The language pair is lower-resource. For language pairs where AI quality is substantially below the high-resource standard (including many African languages, indigenous languages, and less-digitized pairs), the assumptions about AI performance that hold for English to Spanish do not apply. Human review requirements scale with the gap between AI quality and the required quality standard.
The content will be published externally and brand voice matters. 75% of consumers report decreased trust in a brand after encountering poorly translated content. The cost of a brand translation failure compounds with the size of the audience. For content that reaches customers, partners, or regulated audiences, human review is a brand protection measure as much as a quality control measure.
The content involves financial, safety-critical, or regulatory language. Any document where an error in the translation has a direct financial, safety, or compliance consequence requires human review by a qualified professional. The hallucination rate in AI translation is too high to risk in these contexts without a human quality gate.
How does Tomedes' hybrid model solve the accuracy problem?
The accuracy problem in AI translation is not a model selection problem. Every major AI translation model produces fluent output. The problem is that fluent output and accurate output are not the same thing, and no single model reliably identifies its own errors.
Tomedes addresses this at the source with SMART, its proprietary technology that runs content through 22 AI models simultaneously and selects the consensus translation sentence by sentence. When 22 independent systems produce the same output for a given sentence, the probability that translation is correct is substantially higher than any single model's confidence level. When models disagree, that disagreement flags the segment for careful human review.
The SMART consensus draft then moves into a managed workflow with three additional human-expert stages.
Qualified human post-editing. Domain-specialist linguists review the consensus draft for accuracy, terminology, cultural calibration, and brand voice. For legal content, the post-editor is a qualified legal translator. For medical content, a medically qualified translator. For technical documentation, a subject-matter specialist in the relevant field.
Quality assurance. A dedicated QA team validates accuracy, terminology consistency, and formatting across the full content set. For projects requiring certified translation, the QA stage includes the professional attestation that AI output cannot provide.
Project management and reporting. A dedicated project manager owns the workflow from brief to delivery, loads the client's approved style guide and termbase before translation begins, and delivers a quality report documenting what was done, who reviewed each file, and what quality scores were recorded.
This is the structure that allows Tomedes to back every project with a 1-Year Quality Guarantee, because the human expert review at every stage creates the accountability that the accuracy data shows AI alone cannot supply.
For buyers who have tried free AI tools and are asking whether the output is good enough for their documents: the answer depends on the document. For legal, medical, certified, and brand-critical content, it is not — and the data reviewed in this guide explains why. For high-volume, structured, informational content in well-supported language pairs, a managed hybrid workflow delivers the speed and cost advantages of AI with the accuracy and accountability of human expertise.
Request a quote from Tomedes and describe your document type, language pair, and quality requirements. A project manager will recommend the right tier and explain what the workflow looks like for your specific content.
FAQs
Q: What is the accuracy rate of AI translation in 2026?
A: AI translation systems reach approximately 96% accuracy across 133 languages in 2026. However, this figure masks significant variation by document type and language pair. For high-resource language pairs in general domains, AI achieves near-human parity. For legal documents, error rates of 15–25% have been documented in comparative studies. For medical patient-facing content in non-Spanish languages, a high proportion of clinically impactful errors were found in peer-reviewed research at Seattle Children's Hospital. The overall accuracy figure is meaningful for general informational content. For specialized, high-stakes documents, it understates the error rate significantly.
Q: Can AI translation be used for legal documents?
A: For internal comprehension purposes, AI translation is useful as a first pass. For any legal document that will be filed, submitted, signed, or cited in a formal proceeding, qualified human legal translation is required. AI translation tools produced error rates of 15–25% on legal documents in a 2023 comparative study, while professional legal translators maintained accuracy above 98% for the same content. Certified translation (which courts, USCIS, and most regulatory bodies require) cannot be provided by AI and must come from a qualified human professional. Tomedes provides certified legal translation services certified under ISO 17100:2015.
Q: Is AI translation safe for medical documents?
A: Not for patient-facing clinical content in its current form, particularly in non-Spanish language pairs. A September 2025 study published in JAMA Network Open found that AI translations of pediatric discharge instructions were inferior across the board in Simplified Chinese, Somali, and Vietnamese compared to professional human translation, with a high proportion of clinically impactful errors identified. For internal clinical documentation used for staff comprehension, AI may assist workflow. For any document a patient will read and act on (consent forms, discharge instructions, medication guides, patient instructions), human review by a qualified medical translator is required.
Q: Why does AI translation make errors even when it sounds fluent?
A: Because AI translation models optimize for fluency (producing grammatically correct, natural-sounding output) rather than for accuracy in the specialized domain of the source text. Individual top-tier AI models carry a hallucination rate of 10–18% during translation tasks, producing confident, fluent text that is factually or semantically wrong. Domain-specific polysemy (where the same word carries different precise meanings in legal, medical, or technical contexts) is the most common source of fluent-sounding but consequentially wrong AI translations.
Q: When is AI translation good enough without human review?
A: For internal comprehension purposes (understanding the general meaning of a foreign-language document without publishing it), AI translation without human review is generally sufficient. For high-volume, structured, informational content in well-supported language pairs (technical documentation, UI strings, e-commerce product catalogs), AI translation with qualified human post-editing (MTPE) produces publication-quality output. For legal, medical, certified, and brand-critical content, or for content in lower-resource language pairs, human review by a domain specialist is not optional.
Q: What is SMART and how does it improve AI translation accuracy?
A: SMART is Tomedes' proprietary technology that runs content through 22 AI models simultaneously and selects the consensus translation sentence by sentence. When 22 independent systems are compared and most agree, the probability of the consensus translation being correct is substantially higher than any single model's confidence level. SMART addresses the single-engine failure mode (where one model makes a confident, fluent, wrong translation) by requiring agreement across multiple independent systems before a segment is accepted as the starting draft. The consensus output then moves into human post-editing, QA, and project management stages under Tomedes' managed workflow. Every project is backed by a 1-Year Quality Guarantee.

By Rachelle Garcia
Connect on LinkedInRachelle leads product and AI at Tomedes, where she runs the experiments that turn internal data into better translation experiences. She writes about what actually happens when you build AI products such as MachineTranslation.com — the numbers, the surprises, and the parts that don't go to plan.
Share:

Post your Comment