 Add text to get the translation that 22 AI models agree on
Add text to get the translation that 22 AI models agree on


Is Your AI Translation Workflow Costing You More Than It Saves?
You did not set out to build a broken translation workflow. You adopted AI because it was fast, scalable, and significantly cheaper than sending everything to a human translator. For a while, it probably worked well enough. Then the complaints started.
A regional team flagged that the brand voice sounded wrong in one market. A client noticed a terminology inconsistency between two documents. Your content ops lead started spending three hours reviewing every batch before it could go live. A localized campaign launched with a product name rendered three different ways across six markets.
The AI did not get worse. The gap between what AI produces and what your audience actually needs got more visible as you scaled. According to Crowdin's 2026 enterprise AI translation survey of 152 B2B professionals, 55.9% of enterprise teams cite quality consistency (specifically terminology and brand voice) as the primary failure point in model-only AI translation setups. These are not small companies that rushed into AI without thinking. They are teams that adopted AI translation and discovered that the tool was not the problem. The workflow around it was.
This article is for marketing and content ops leads who are already using AI translation, are already running into these problems, and are trying to decide what to do next.
Table of Contents
- How do you know your AI translation workflow is broken?
- Why does AI translation produce inconsistent brand voice across markets?
- Why does AI translation create terminology problems at scale?
- What is the rework trap and how much is it actually costing you?
- Why is your LSP's AI translation workflow still producing rework?
- What does a workflow that actually works look like?
- What is SMART and why does the starting draft matter so much?
- What does "managed" mean in practice for a marketing ops team?
- How do you evaluate whether managed AI translation is right for your volume?
- FAQs
How do you know your AI translation workflow is broken?
The clearest signal is not a single catastrophic error. It is the slow accumulation of friction that your team has learned to work around.
Run through these questions honestly.
Is someone on your team reviewing every AI translation batch before it publishes? If yes — how long does that take per week, and is that person a qualified linguist or someone who speaks the language well enough to catch obvious problems? The first scenario is a quality control function that belongs in the translation workflow. The second is a risk exposure that is invisible until something gets through.
Have you received a complaint about brand voice or tone from a regional team, a client, or a customer in the past six months? A complaint about brand voice in a translated market is almost never about the words themselves. It is about the register, the formality level, the cultural calibration of the message. AI models optimize for fluency, not for your brand's specific voice. At low volume, this is tolerable. At scale, it compounds into a brand consistency problem that is expensive to undo.
Do your translated documents use the same terminology consistently across all files? Pick one product name, one legal term, or one brand-specific phrase. Search for it across your translated content from the past year. If it appears in more than one form across documents, your workflow has no termbase enforcement. That inconsistency is visible to your audience even when they cannot articulate why the content feels unreliable.
Are your translated files going straight to publish, or do they need formatting work first? If your team is reformatting translated files (adjusting text boxes, fixing layout overflow, correcting font rendering, or handling right-to-left layout issues), that work is a workflow gap, not a document management problem. It is DTP work that belongs inside the translation production process.
Has a translated file ever been published with an error that made it through your review? Not because your reviewer was careless, but because the error was plausible-sounding on a quick read. AI's incorrect solutions are often plausible on the surface, making mistakes difficult to catch without qualified domain review. A fluent-sounding error in a product description, a legal document, or a regulated communication is the most dangerous kind — because it reads correctly to someone without domain expertise and reads wrongly to exactly the audience it was written for.
If you answered yes to two or more of these, your workflow is broken. Not dramatically broken — broken in the way that creates slow, compounding costs that never appear as a single line item on any budget.
Why does AI translation produce inconsistent brand voice across markets?
Brand voice is the accumulation of deliberate choices (about register, formality, tone, vocabulary, and cultural framing) that distinguish how your company communicates from how every other company communicates. Building it in English takes years of editorial decisions and internal alignment. Preserving it in translation requires those same decisions to be made, explicitly, in every target language.
AI models do not make those decisions. They make the most statistically probable linguistic choices based on their training data. The most probable choices are not your brand voice, they are the average of how similar content has been written across the internet in that language.
The result is a translated version of your content that sounds like a competent approximation of your brand rather than your brand. In individual documents, the difference is subtle. Across a full content ecosystem (website, product documentation, campaign copy, customer communications), the cumulative drift is significant and recognizable.
The specific failure modes are consistent. Formal English brand voices get translated into a register that reads as cold or bureaucratic in languages with richer formality gradations. Conversational tones get flattened into MSA-style neutral Arabic or formal German that reads as institutional. Product names and brand-specific terms get translated literally when they should be preserved, or preserved when they contain puns or cultural references that need adaptation. Cultural references land wrong because the model has no way of knowing which references are loadbearing and which are decorative.
None of this is a criticism of AI models. It is a description of what they are designed to do. They are designed to produce fluent, natural-sounding target language. Preserving a specific brand voice requires information about that voice — documented, specific, and loaded into the workflow before translation begins. That is a workflow function, not a model function.
Why does AI translation create terminology problems at scale?
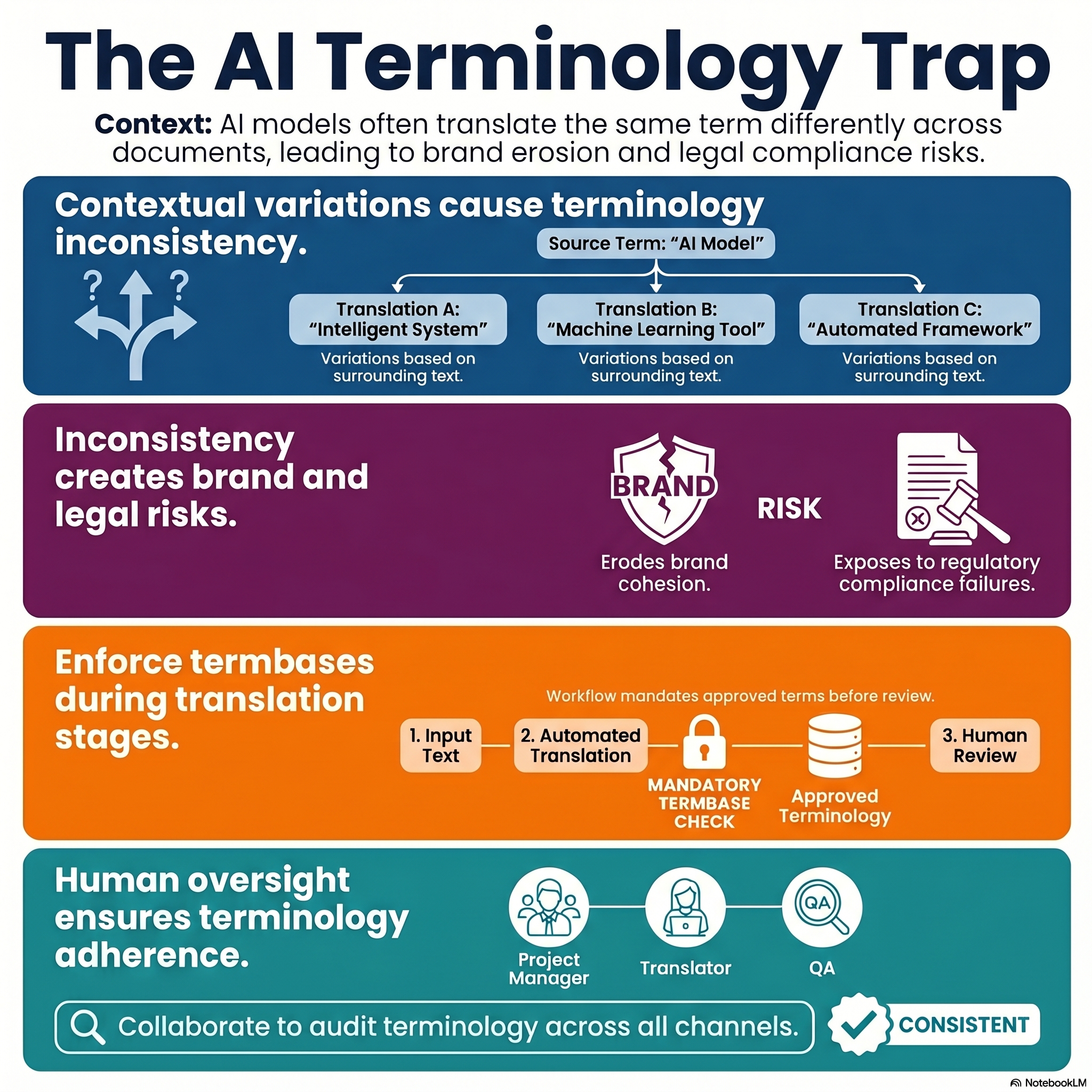
Terminology inconsistency is the brand voice problem's more technically specific cousin. Where brand voice is about how you sound, terminology is about what you call things — and in a translation workflow without termbase enforcement, what you call things changes from document to document.
The mechanism is straightforward. An AI model encountering the same source term in two different documents, with different surrounding context, will often produce two different translations. Both will be plausible. Neither will be wrong in isolation. Together they create a content set in which your product has two names, your legal framework has two phrasings, and your brand promise is articulated three different ways depending on which document a customer reads first.
For marketing content, this erodes brand cohesion. For technical documentation, it creates user confusion. For legal or regulated content, it creates compliance exposure — because regulatory bodies expect precise, consistent terminology and will flag inconsistency as evidence of unreliable translation.
A generic AI model may miss domain-specific language or repeat the wrong term across a document and across channels. The solution is not a better AI model. It is a workflow that enforces an approved termbase at the translation stage, before the human reviewer even sees the output. That enforcement does not happen automatically. It requires a project manager who loads the termbase at intake, a translator who works against it, and a QA function that audits adherence across the full content set.
What is the rework trap and how much is it actually costing you?
The rework trap is what happens when the cost of reviewing and fixing AI translation output is not tracked against the cost of the translation itself, so the workflow appears cheap on the invoice and expensive in practice.
Here is how it accumulates. Your AI translation tool costs a fraction of human translation per word. The output requires review before it can publish. Someone on your team (or a freelancer, or a bilingual employee whose primary job is not translation) spends time reviewing it. Some of what they catch is obvious. Some of what gets through is not obvious until a client flags it or it appears in a published document. When an error is caught after publication, it requires a correction cycle that involves finding the error, getting it fixed, republishing, and in some cases communicating to customers or partners that content was incorrect.
When a single-engine translation contains errors, the cost of fixing those mistakes after delivery often exceeds the original translation cost. That figure does not include the internal labor of the reviewer who did not catch it, the time of the person who handled the client complaint, or the reputational cost of publishing incorrect content in a market you are trying to build credibility in.
The rework trap is particularly acute for marketing and content ops teams because translation is not their core function. They are adopting AI to solve a volume problem (to produce multilingual content at the speed their publishing calendar requires) and they are absorbing the quality gap as internal labor because that seems less disruptive than slowing down. It is less disruptive in the short term. Over a year of high-volume multilingual content production, it is a significant and untracked cost.
Why is your LSP's AI translation workflow still producing rework?
This question matters because many organizations reading this have already moved from DIY AI translation to using a language service provider, and still have the same problems. The invoice is different. The output problems are familiar.
The reason is that most LSPs offering "AI translation" or "AI-assisted translation" are doing one of two things. They are running a single MT engine and having a post-editor review it — which improves quality but does not solve the consistency problem, because the starting draft still varies with the engine's performance on different content types and language pairs. Or they are running AI as an internal efficiency tool but still billing and delivering at the same pace as before, without the managed workflow infrastructure that would produce genuinely consistent output.
Neither approach addresses the root cause. The root cause is not which AI engine is used. What breaks without a platform layer is not AI itself but the operating environment around it — context, consistency, coordination, and deployment. These are infrastructure problems, not model problems.
The questions to ask an LSP claiming to offer AI translation:
What is the AI component specifically — which engine or engines, and how is the starting draft generated? How is the starting draft different from what a single MT engine would produce? How is terminology enforced before the post-editor sees the output? What QA documentation is produced and what does it contain? Who is accountable for the final output, and what is the guarantee if an error is found after delivery?
If the answers are vague, the workflow is generic. Generic AI translation workflows produce generic AI translation problems.
What does a workflow that actually works look like?
A managed AI translation workflow that solves the problems described above has five stages. The presence or absence of any one of them is the difference between a workflow that compounds your content quality and one that undermines it.
Stage 1: Brief and routing. Before a single word is translated, the project manager reviews the content, loads the client's style guide and approved termbase, and routes each content type to the appropriate workflow tier based on risk level and priority. High-risk content (legal, regulated, brand-critical) gets full post-editing and QA. Lower-risk content moves through a lighter review cycle. The routing decision is made by a human with knowledge of the client's content landscape, not by an algorithm applying a default setting.
Stage 2: SMART draft generation. Tomedes' SMART technology runs the content through 22 AI models simultaneously and selects the consensus translation (the output that the greatest number of models agree on, sentence by sentence) as the starting draft. This is not a single MT engine. It is 22 independent systems compared against each other, with the most reliable output selected as the basis for human review. The starting draft that reaches post-editors is more consistent, more accurate, and requires less correction than single-engine output.
Stage 3: Human post-editing. Expert linguists with domain expertise in the content type review and refine the SMART draft for fluency, cultural calibration, and brand voice. They work against the approved style guide and termbase loaded at stage one. This is not a fluency check. It is a qualified professional applying domain and cultural knowledge that no AI model possesses.
Stage 4: QA and DTP. A dedicated QA team validates accuracy, formatting, and terminology consistency across the full content set. Multilingual DTP specialists check layout, fonts, spacing, and script rendering to produce files that are publish-ready — not files that need another internal formatting pass before they can go live.
Stage 5: Delivery and reporting. The project manager delivers final files alongside a transparent report documenting what was done, who reviewed each file, what quality scores were recorded, and what the cost breakdown shows. This report is the accountability layer that makes the workflow improvable over time — because it identifies which content types require the most post-editing effort, which signals where source content quality needs attention.
What is SMART and why does the starting draft matter so much?
Most AI translation failures that marketing ops teams attribute to "AI being wrong" are actually starting-draft problems that human review was not resourced to catch.
When a single AI engine produces a starting draft, that draft reflects one system's strengths and weaknesses. High-frequency language pairs like English to Spanish or English to French produce relatively reliable single-engine output. Less common pairs, technical domains, or culturally specific content all reduce single-engine reliability. The post-editor working on that draft is correcting from a baseline that may have significant errors in specific segments — and at high volume, those corrections require more time and expertise than the review budget typically allows for.
SMART changes the starting baseline. By running 22 models and selecting the consensus output, SMART produces a draft in which the segments most likely to contain errors have already been filtered by the disagreement between models. When 22 models disagree on a translation, that disagreement is a signal that the segment requires careful review. When 22 models agree, the probability of that translation being correct is substantially higher than any single engine's confidence level.
The practical effect is that post-editors working on a SMART draft spend less time correcting fundamentals and more time applying the judgment that only humans provide — cultural calibration, brand voice, domain accuracy. The quality ceiling rises because the starting point is higher.
According to Crowdin's 2026 managed AI translation case study, 75% of translations in a properly managed AI workflow were publication-ready without edits — yet 100% were still reviewed by qualified human editors. That combination (a high proportion of strong AI output, with 100% human oversight) is what a managed workflow with a strong starting draft produces. It is not achievable with a single engine and a light review pass.
What does "managed" mean in practice for a marketing ops team?
For a marketing or content ops lead, the practical meaning of "managed" is that translation stops being a task your team absorbs and becomes a service your team briefs.
The workflow before managed AI translation typically looks like this: export content, run it through your MT tool, download the output, send it to a bilingual team member or freelancer for review, receive corrections, reformat the file, send it for a second look, make final edits, upload. Each step takes time. Each handoff creates a delay. Each review is only as good as the reviewer's language proficiency and domain knowledge, which is rarely guaranteed.
The workflow after managed AI translation looks like this: brief Tomedes with your content, your style guide, your approved termbase, and your deadline. Receive publish-ready files with a quality report. That is the full scope of the marketing ops team's involvement.
The difference is not only in time saved. It is in what your team is actually spending its time on. A content ops lead who is not reviewing translation output has more capacity for the work that requires their specific expertise. A brand that is not managing a freelance review network for every market has fewer coordination failure points. An organization that receives a quality report instead of unreviewed output has documentation it can use for compliance, reporting, and continuous improvement.
For teams scaling into new markets, the managed model also means that quality is consistent from market one to market twenty — because the same workflow, the same termbase, and the same QA standards apply to every project regardless of language pair.
How do you evaluate whether managed AI translation is right for your volume?
Three questions determine whether managed AI translation is the right fit.
Is your monthly translation volume high enough that quality inconsistency is compounding? Managed AI translation delivers the most value when inconsistency across a body of content is costing you more than the translation itself. For low-volume, one-off projects, standard professional translation is often the simpler option. For ongoing content programs (regular campaign localization, product documentation updates, multilingual content calendars), managed AI translation provides the infrastructure that makes consistency possible at scale.
Is your content brand-sensitive or regulated? If your translated content is customer-facing, carries legal weight, or operates in a regulated industry where terminology accuracy has compliance implications, the investment in a managed workflow with documented QA is directly proportional to the cost of the errors it prevents. If your translated content is internal-only and low-stakes, a lighter workflow may be sufficient.
Is your current workflow producing internal friction? If someone on your team is spending meaningful time reviewing, correcting, or reformatting AI translation output each week, that is the clearest possible signal that the cost of the current workflow is not what appears on the invoice. A managed workflow externalizes that cost, resolves it with qualified expertise, and returns that time to your team.
If all three of these apply to your organization, managed AI translation is not a premium option. It is the cost-effective alternative to a workflow that is already costing more than it appears to.
Request a quote for Tomedes Managed AI Translation Services and describe your content volume, language pairs, and current workflow to a dedicated project manager. The first conversation is a diagnosis, not a sales call.
FAQs
Q: We already use an LSP for AI translation. Why are we still getting rework?
A: Because most LSP AI translation workflows use a single MT engine with a post-editing pass — which improves individual translation quality but does not solve consistency across a content body, termbase enforcement, or DTP. What breaks in model-only setups is not the AI itself but the operating environment around it — context, consistency, coordination, and deployment. If your current LSP cannot tell you specifically how the starting draft is generated, how terminology is enforced before post-editing, and what QA documentation you receive, the workflow is generic. Generic workflows produce the same consistency and rework problems regardless of how good the underlying model is.
Q: What makes SMART different from using a single best-in-class MT engine?
A: SMART runs 22 AI models simultaneously and selects the consensus translation (the output most models agree on) sentence by sentence. A single best-in-class engine has specific failure modes: gaps in its training data, biases toward particular register choices, weaknesses in specific language pairs or domains. When 22 independent systems are compared and most agree, the probability of the consensus translation being correct is substantially higher than the probability of any single engine's output. The post-editors working on a SMART draft start from a stronger baseline, which means more of their review time is spent on the cultural and domain judgment that only humans can provide.
Q: How does Tomedes enforce our brand voice across languages?
A: At project intake, your style guide, preferred terminology, tone guidelines, and any existing approved translations are loaded into the workflow before translation begins. Post-editors work against these documents. The QA stage audits adherence across the full content set. The project report documents where approved terms appeared and flags any deviations. If your organization does not yet have a formal style guide or termbase, Tomedes' project managers can advise on building one as part of the first project — so that every subsequent project benefits from the accumulated brand and terminology decisions.
Q: What is the 1-Year Quality Guarantee and what does it cover?
A: Every Tomedes project is backed by a 1-Year Quality Guarantee. If a translation error attributable to Tomedes' workflow is identified within one year of delivery, Tomedes corrects it at no additional cost. This guarantee is only possible because qualified human experts review and approve every output before delivery. It is not a policy that applies to automated output. It is an accountability commitment that only a managed, human-in-the-loop workflow can make.
Q: How long does a managed AI translation project take compared to our current process?
A: Turnaround depends on volume, language pairs, and content complexity. For most marketing content volumes, the difference between managed AI translation and your current workflow is not primarily in clock time — it is in the elimination of the internal review and formatting cycles that follow delivery. Files arrive publish-ready, with a quality report. Your team does not receive a draft that needs another pass before it can go live. For large-volume projects with tight deadlines, Tomedes' project managers work with clients to design a delivery schedule at intake rather than discovering timeline issues after work has begun.
Q: We are expanding into three new markets simultaneously. Where do we start?
A: Start with the market where content quality failure carries the highest cost — whether that is reputational, regulatory, or commercial. Brief Tomedes with your highest-priority language pair, your existing brand documentation, and a sample content set. The first project establishes the style guide, termbase, and workflow configuration that scales to the other two markets without starting from zero on each. Contact a Tomedes project manager to discuss your expansion timeline and content calendar.

By Ofer Tirosh
Connect on LinkedInOfer Tirosh is the founder and CEO of Tomedes, a language technology and translation company that supports business growth through a range of innovative localization strategies. He has been helping companies reach their global goals since 2007.
Share:

Post your Comment