 Add text to get the translation that 22 AI models agree on
Add text to get the translation that 22 AI models agree on


Why people stopped trusting single-model AI for business translations
In the initial rush of the Generative AI boom, the corporate world fell for the myth of the "universal translator." The promise was simple: integrate one powerful Large Language Model (LLM) like ChatGPT, Gemini, or Claude, and your global communication worries would vanish.
By 2026, the industry has officially entered "Act Two". We have moved past task-level experimentation and into the reality of outcome-driven automation. For global enterprises, this transition has revealed a hard truth: relying on a single AI model is no longer a shortcut – it is a dangerous single point of failure.
(Source: Slator Pro Guide: Translation AI (2025) and MachineTranslation.com.)

This guide explores the specific risks of single-model dependency and provides a blueprint for building a resilient, multi-model translation strategy.
Table of Contents
What is the risk of using a single AI model for translation?
How often do AI models hallucinate in business documents?
Which European languages are hardest for AI to translate?
How does a 22-model SMART consensus system filter out errors?
What is the ROI of multi-model AI vs human translation?
How do I create a secure global brand strategy with AI?
FAQs
What is the risk of using a single AI model for translation?
A single-model approach assumes that one AI model is equally proficient across all language pairs, domains, and cultural contexts. Industry data shows this is mathematically impossible. Every AI model has idiosyncratic "blind spots" based on its training data.
Model performance drift: A model that excels at European "flow" might fail at technical accuracy. For instance, while DeepL maintains high accuracy for flow at 94.2% , ChatGPT averages 89.8% and is prone to inventing facts in business text.
The “black box” risk: When a single model makes a mistake – such as hallucinating a legal precedent or misinterpreting a safety contraindication – there is no internal "second opinion" to flag the error.
Shadow AI proliferation: Without a centralized multi-model strategy, departments often use different tools (DeepL for marketing, ChatGPT for internal emails), leading to a fragmented and inconsistent brand voice.
How often do AI models hallucinate in business documents?
In business translation, a "hallucination" isn't just a quirky error; it's a legal and operational liability. Individual top-tier LLMs fabricate content between 10% and 18% of the time.
(Data synthesized from Intento State of Translation Automation 2025 and MachineTranslation.com.)

In highly regulated sectors, these errors have catastrophic consequences:
Sector | Usage Rate | Hallucination Risk | Real-World Consequence |
Legal | 23% | 10-18% | Fabricated legal precedents or subtle clause mistranslations. |
Healthcare | 19% | 10-18% | Omitted contraindications or dosage formatting errors. |
Finance | 17% | 10-18% | Inconsistent financial terminology in quarterly reports. |
Actionable Insight: For any document where a 10% error rate is unacceptable, you must move beyond a single-pass translation into a verification-first workflow.
Which European languages are hardest for AI to translate?
Many businesses assume that because French and Spanish translations are "solved," the rest of Europe is equally easy for AI. This assumption leads to the European Complexity Gap.
(Source: Tomedes and Lokalise AI Translation Quality Research (2025).)
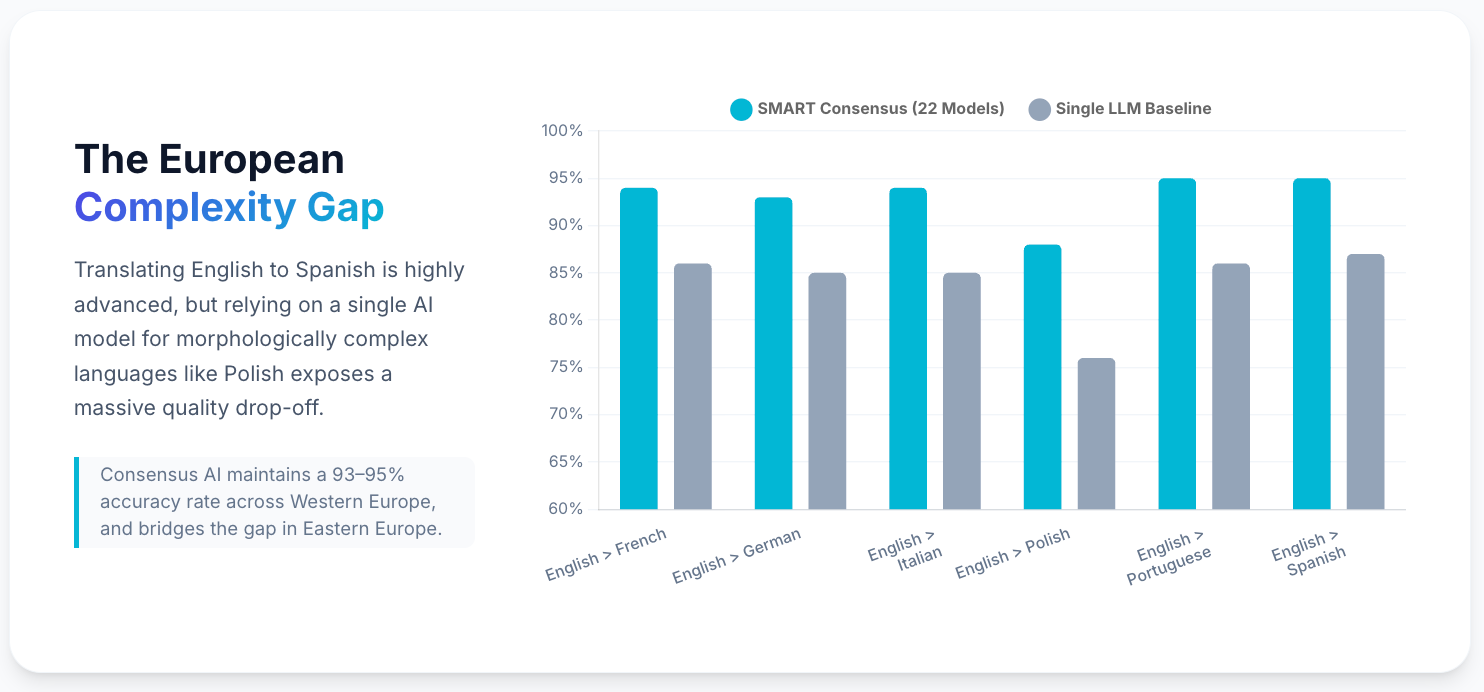
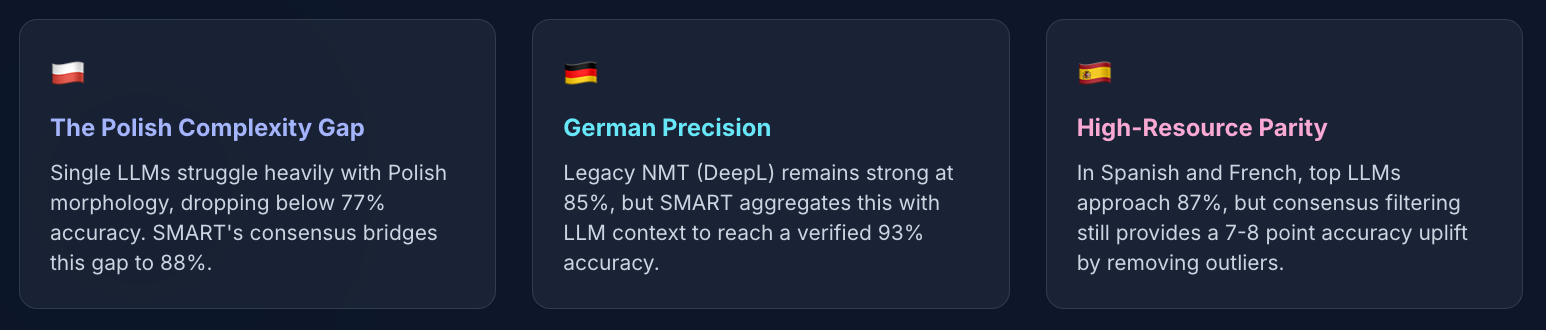
Standalone LLMs often plateau at 84-87% accuracy for high-resource languages due to formatting errors and terminology drift. However, the drop-off for morphologically complex languages like Polish is much steeper, with single-model accuracy falling to just 76%.
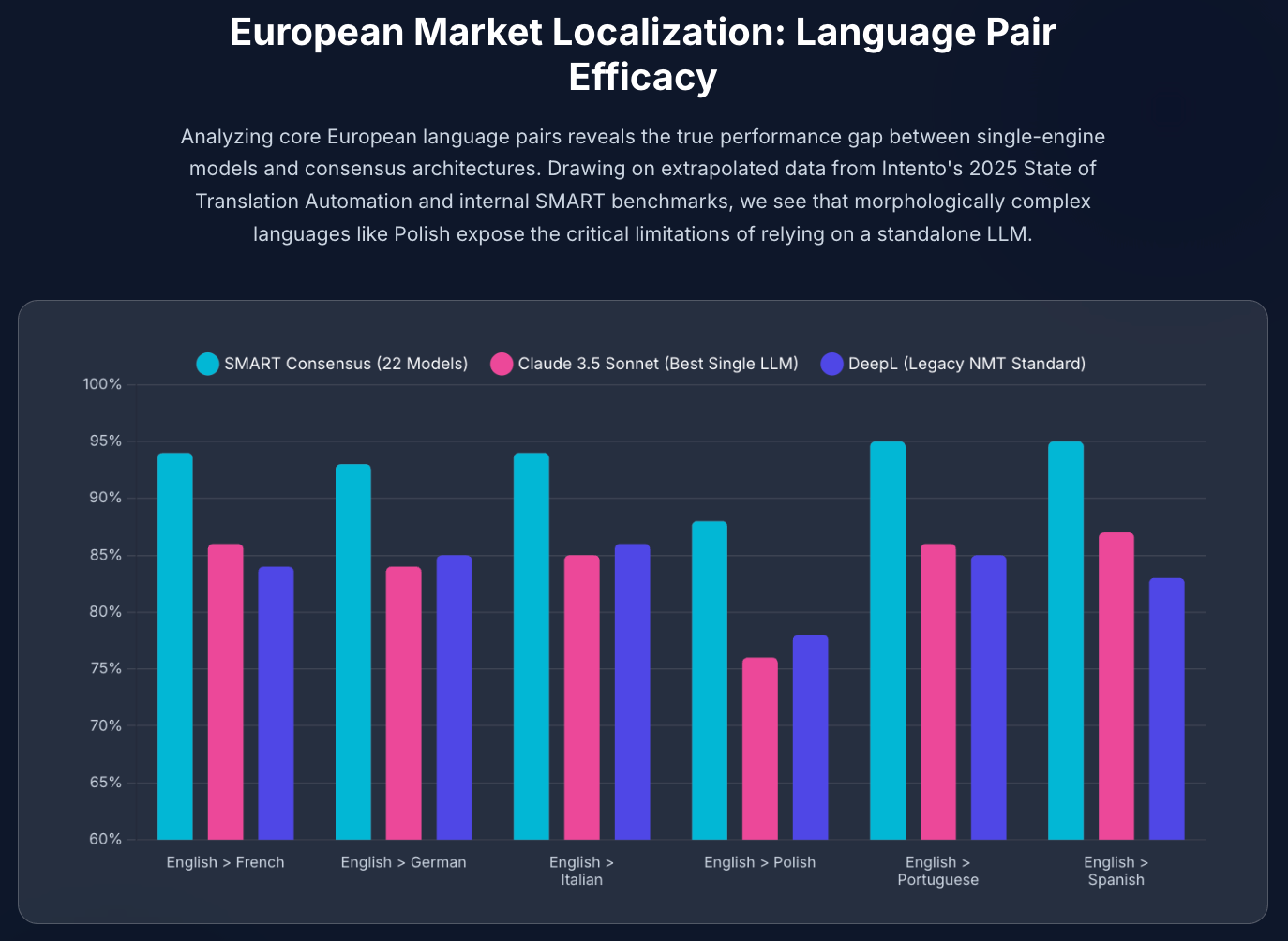
By contrast, a consensus approach that aggregates model strengths maintains 93-95% accuracy in Western Europe and boosts Polish accuracy to 88%.
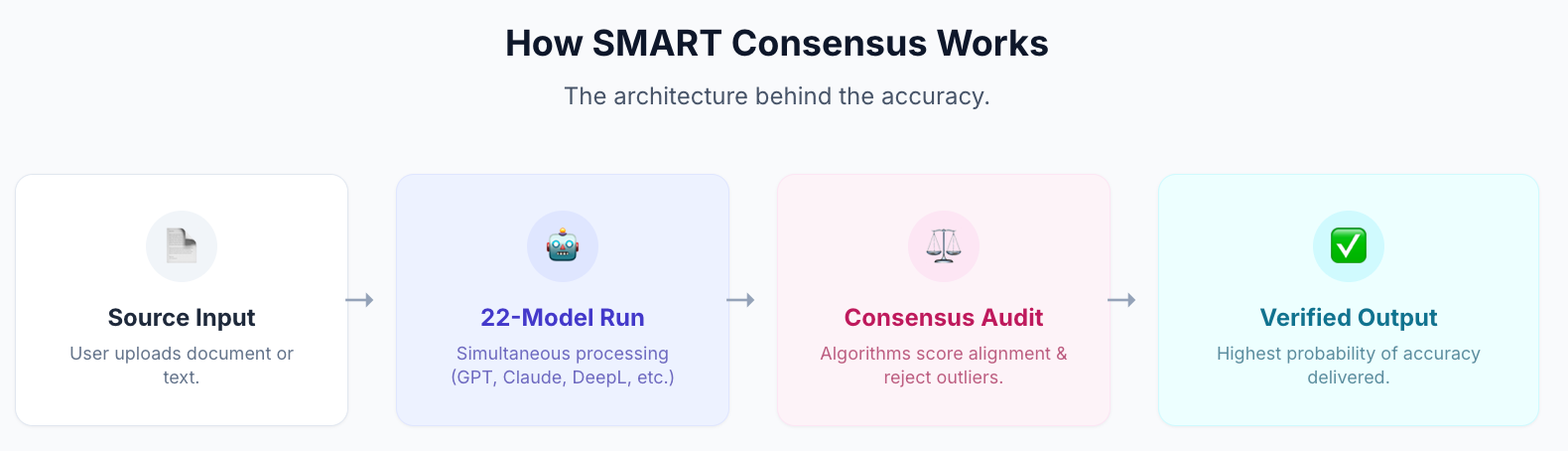
How does a 22-model SMART consensus system filter out errors?
The industry is shifting from generation to verification. The most reliable way to mitigate single-model bias is through SMART technology – a system that orchestrates a real-time consensus among 22 independent AI models.
Majority voting: If the majority of the models agree on a term, the system automatically selects this.
Sentence-level analysis: The system doesn't just pick the "best overall" document; it selects the mathematically optimal translation for every single sentence based on the consensus of the AIs.
Result: While a standalone engine like ChatGPT scores 94.2 on accuracy, the SMART consensus approach achieves an aggregated score of 98.5.
(Benchmarking data via MachineTranslation.com internal reports and WMT24 General Machine Translation Findings.)
What is the ROI of multi-model AI vs human translation?
Relying on one AI model often increases internal workload rather than reducing it. 46% of non-linguists report spending more time manually comparing different AI outputs than the AI actually saved them.
Switching to a managed, multi-model workflow provides measurable business gains:
Time savings: SMART technology users spend 24% less time fixing errors than those who pick an AI model manually.
Speed-to-Market: Companies using "agentic" multi-layer approaches reach their markets 2.5x faster.
Cost Efficiency: Tomedes Managed AI typically offers 80-90% savings over pure human workflows while maintaining 98% terminology consistency.
How do I create a secure global brand strategy with AI?
To move from a liability-prone "single-model" setup to a resilient global architecture, follow these steps:
Audit your toolset: Stop using one general LLM for all language pairs. Identify which models (DeepL, Google, Microsoft, specialized LLMs) perform best for your specific target regions.
Centralize governance: Use an aggregator platform to eliminate "shadow AI" and ensure every department follows the same quality and security protocols.
Implement consensus verification: For high-stakes content, use a translation tool that cross-references at least 10+ models to filter out hallucinations.
Enforce sovereign data security: 92% of enterprise clients prioritize confidentiality. Ensure your multi-model workflow uses private instances to prevent data from training public models.
FAQs
Q: Why isn't a single "super-model" like ChatGPT enough?
A: Even the most advanced models produce model-specific errors (hallucinations) roughly 10-18% of the time. Without a consensus mechanism to cross-verify the output, you have no way to programmatically catch these errors before they reach your customers. (Data synthesized from Intento State of Translation Automation 2025 and MachineTranslation.com.)
Q: Does multi-model translation make the process slower?
A: Actually, it's faster. Because the first draft is significantly more accurate (reducing error-drift by 18-22%), humans spend 24% less time doing repetitive post-editing.
Q: Is it more expensive to use 22 models?
A: By using a consensus system like Tomedes’ SMART, you bypass the cost of manual comparison and extensive rework. Multi-model workflows typically yield 80-90% savings over traditional methods by automating the "verification layer" that used to require manual human intervention.
Post your Comment